Razzia van Rotterdam Digitaal

Het digitaliseringsproject Razzia van Rotterdam Digitaal liep van 18 februari tot 1 maart 2025. Binnen dit project digitaliseerde en ontsloot het NIOD Instituut voor Oorlogs-, Holocaust- en Genocidestudies de onderzoekscollectie van historicus Ben Sijes over de Rotterdamse razzia’s van 10 en 11 november 1944. De collectie is nu digitaal beschikbaar en beter doorzoekbaar gemaakt voor zowel onderzoekers als een breed geïnteresseerd publiek.
Een unieke onderzoekscollectie
Tijdens deze razzia’s werden in november 1944 ongeveer 52.000 mannen in korte tijd van huis weggevoerd en ingezet voor dwangarbeid in Nederland of Duitsland. Historicus Ben Sijes, destijds werkzaam bij het Rijksinstituut voor Oorlogsdocumentatie (het huidige NIOD), verzamelde tussen 1946 en 1951 een omvangrijke hoeveelheid documentatie voor zijn boek De razzia van Rotterdam, 10-11 november 1944 (1951).
Sijes verzamelde in totaal bijna zes meter aan archiefmateriaal, nu ondergebracht in Collectie Onderzoekingen 258: Razzia van Rotterdam. De collectie bevat onder meer vragenlijsten, persoonlijke brieven, correspondentie, interviewverslagen en onderzoeksnotities. Sijes sprak met een brede groep betrokkenen, waaronder slachtoffers van de razzia, verzetsmensen, ambtenaren en andere tijdgenoten. Omdat veel materiaal kort na de gebeurtenissen werd verzameld, bieden de documenten een zeldzaam directe blik op de ervaringen tijdens de razzia’s én op de vroege naoorlogse geschiedschrijving.
Digitalisering en transcriptie
Binnen het project is de volledige papieren collectie gedigitaliseerd. Alle scans zijn getranscribeerd met behulp van een hybride methode, waarbij automatische tekstherkenning is gecombineerd met handmatige controle en correctie. Het transcriptieproces begint steeds met lay-outherkenning (zie afbeelding 1). Daarbij identificeert het systeem eerst de structuur van de pagina en lokaliseert het de afzonderlijke tekstregels. De beelden laten zien hoe de software eerst de structuur van de pagina (tekstregels) bepaalt, waarna de tekst kan worden omgezet naar machineleesbare vorm.
In totaal zijn 29.838 pagina’s uit 347 inventarisnummers gescand. Deze scans zijn vervolgens automatisch getranscribeerd met behulp van Automated Text Recognition (ATR) en daarna handmatig gecontroleerd. Dankzij dit proces zijn de documenten nu full-text doorzoekbaar.

Structuurherkenning en onderzoeksdataset
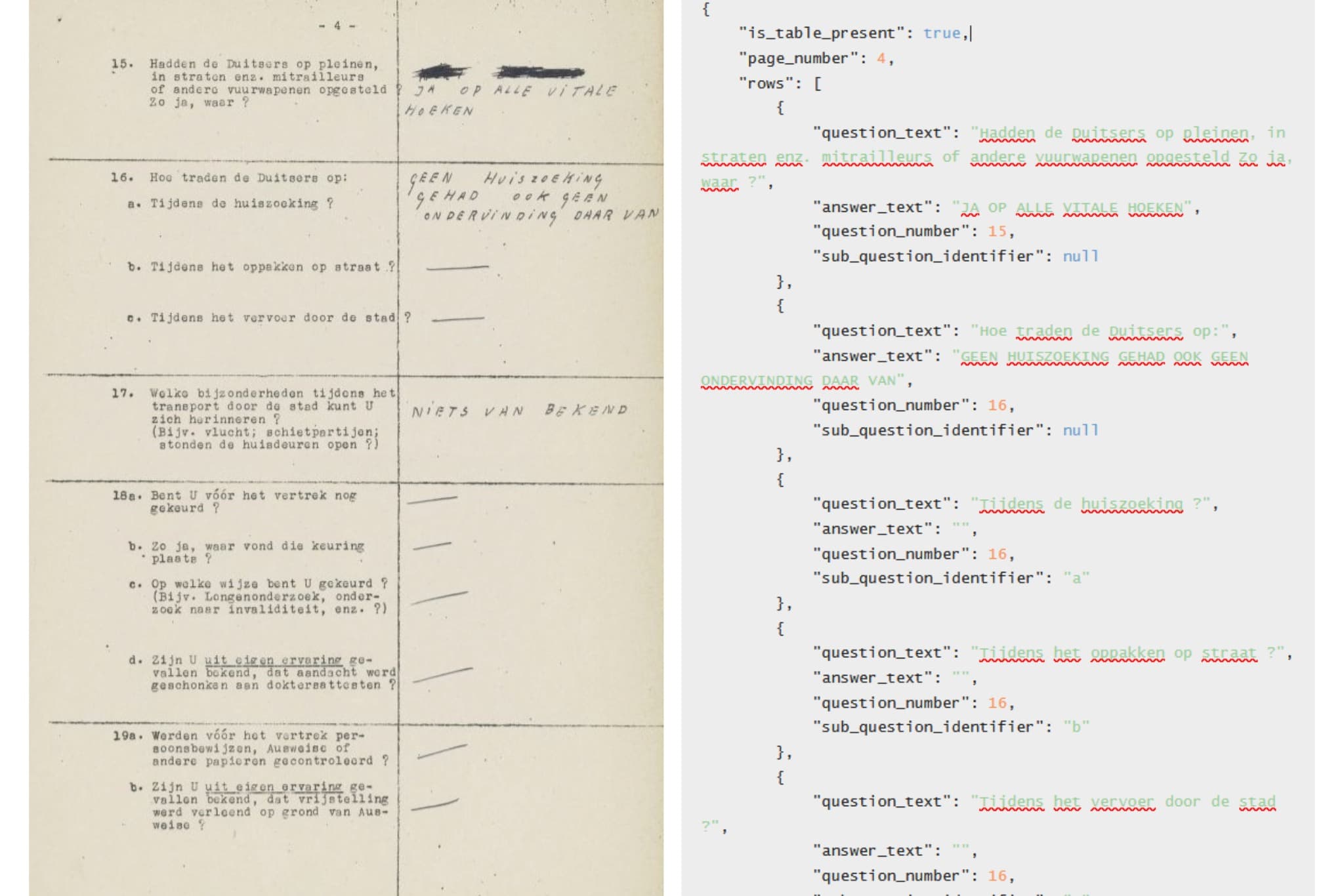
Een belangrijk deel van de collectie bestaat uit enquêteformulieren. Voor deze formulieren zijn modellen ontwikkeld die automatisch de tabelstructuren (velden) in de vragenlijsten herkennen. Hierdoor worden niet alleen de woorden herkend, maar ook de structuur van het formulier: welke tekst een vraag is en welk handgeschreven antwoord daarbij hoort. De gegevens uit de formulieren zijn zo omgezet naar gestructureerde data en opgeslagen in JSON- en ALTO-formaten.
Op afbeelding 2 hieronder is links een gescand enquêteformulier te zien. Met behulp van een computermodel zijn de tabelstructuren automatisch herkend. Rechts is zichtbaar hoe het systeem deze informatie omzet naar een digitaal formaat, waarbij per vraag het vraagnummer, de vraagtekst en het bijbehorende antwoord afzonderlijk worden uitgelezen.
Het verschil met een gewone transcriptie is dat de informatie nu per veld en per vraag analyseerbaar wordt. Hierdoor kunnen onderzoekers bijvoorbeeld alle antwoorden op een specifieke vraag met elkaar vergelijken, patronen herkennen in grote aantallen formulieren en gegevens over personen, gebeurtenissen of ervaringen systematisch onderzoeken.
Nieuwe zoekmogelijkheden
Naast de verrijking van de klassieke archiefinventaris is binnen het project een aanvullende zoekingang ontwikkeld met aanvullende informatie over personen uit de collectie. Deze toegang maakt het mogelijk om personen te vinden op basis van bijvoorbeeld de naam, geboortedatum, geboorteplaats of arrestatiedatum. Hierdoor kunnen individuele personen eenvoudiger worden teruggevonden en kan informatie uit de collectie beter worden verbonden met andere erfgoedbronnen.
Koppeling met andere collecties
Binnen het project werd o.a. samengewerkt met het Stadsarchief Rotterdam en Stichting WO2NET. Dankzij deze samenwerking konden aanvullende biografische gegevens aan personen uit de collectie worden gekoppeld. Via deze koppelingen kunnen bezoekers worden doorverwezen naar gerelateerde bronnen en aanvullende informatie op andere platforms. Dit maakt het mogelijk om gegevens uit verschillende erfgoedcollecties met elkaar te verbinden en gebeurtenissen en personen beter in hun historische context te onderzoeken.
Waar zijn gegevens te raadplegen?
De collectie en aanvullende informatie over de Rotterdamse razzia zijn via verschillende platforms toegankelijk:
Collectie 258 Onderzoeken betreft scans en transcripties over de Razzia van Rotterdam
De deelcollectie Razzia van Rotterdam bevat ingevulde vragenlijsten, correspondentie met verschillende instanties en verslagen van gesprekken, manuscripten.
Onderzoeksdata van het project Razzia van Rotterdam Digitaal
Razzia van Rotterdam Digitaal (R2D): Dataset Collection from the Ben Sijes Research Archive on the Rotterdam Razzia (1946–1951) op DANS Data Station Social Sciences and Humanities.
Stadsarchief Rotterdam
Hier is onder andere informatie te vinden over de weggevoerde Rotterdammers.
Oorlogsbronnen.nl
Hier is onder andere een themadossier over de Rotterdamse razzia te vinden.
Dankwoord
Het NIOD bedankt het Stadsarchief Rotterdam en Stichting WO2NET voor hun samenwerking en ondersteuning bij het project. In het bijzonder gaat onze dank uit naar Ron Schuurmans voor zijn bijdrage aan de biografische ontsluiting van personen uit de collectie, en naar onze collega’s van HuC, Stefan Klut en Rutger van Koert, voor hun tabelextractie- en transcriptiewerkzaamheden.
Het project Razzia van Rotterdam Digitaal werd mede mogelijk gemaakt door financiële ondersteuning van het Mondriaan Fonds.
Team

Anne van Mourik
Postdoctoraal onderzoeker aan Sciences Po en podcastmaker bij het NIOD

Anne van Mourik
Postdoctoraal onderzoeker aan Sciences Po en podcastmaker bij het NIOD

Anne van Mourik
Postdoctoraal onderzoeker aan Sciences Po en podcastmaker bij het NIOD

Anne van Mourik
Postdoctoraal onderzoeker aan Sciences Po en podcastmaker bij het NIOD

Anne van Mourik
Postdoctoraal onderzoeker aan Sciences Po en podcastmaker bij het NIOD
Meld je aan voor de nieuwsbrief
Blijf elke maand op de hoogte van nieuwe publicaties, evenementen en meer.
NIOD
Herengracht 380
1016 CJ Amsterdam
Openingstijden studiezaal
Di - Vr: 09:00 - 17:30 uur
Gesloten op maandag
Let op:
Het NIOD zelf is op maandag gewoon geopend.